I have to start by saying it out loud – Terraform is pretty nice. It really makes Infrastructure as Code – very very real. For a person like me coming from a Software Engineering/System Engineering background this takes the infrastructure to a level where it can be pulled in (if not into) the software engineering teams, then at least very, very close to. The word here is agility.
AWS and Terraform
My experience with Terraform is pretty young (at the time of writing somewhere between 48 and 72 hours) – which makes me vulnerable to being capable of seeing all the benefits, but haven’t really seen the risks yet. After first spending some hours randomly googling (which was also very productive) I hit the course on Terraform on LinkedIn learning. That is the only background here.
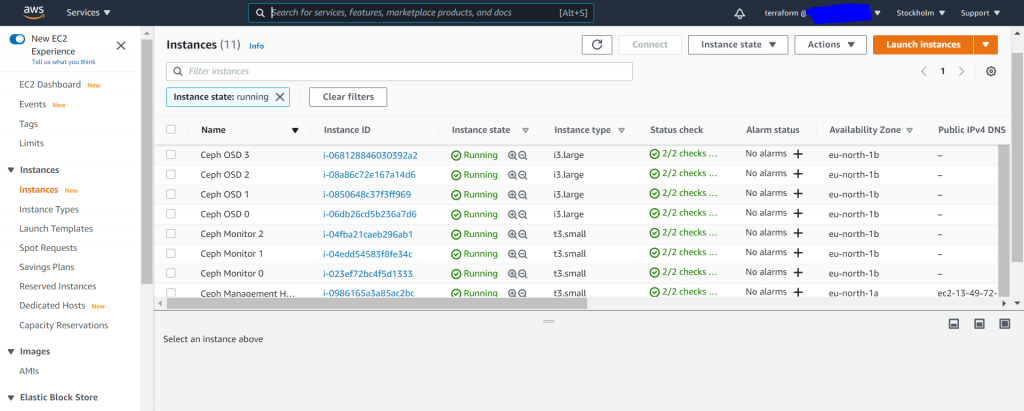
In below screenshot – is the spun-up hosts from my “Ceph on AWS” testing I’m currently trying to do (Another article on the sanity of running Ceph in AWS) – Terraform code on Github
Terraform and Providers.
In Terraform “AWS” is called a provider and searching at the Terraform registry delivers a awful lot of providers. Searching delivers way more than 200 different providers – and a registry very full of modules ready to use.
What is the value?
To agile development teams – this delivers the ability to take the Infrastructure into the sprint cycles.
Want you application seperated out into a seperate subnet? (Done!)
What a load-balancer deployed? (Done!)
Want to push firewall in place around the infrastructure? (Done!)
It is very easy to use, but the underlying understanding of how infrastructure works is still needed to get things correctly configured up.
Remember that in many cases – the alterative is to deliver wish list to the infrastructure team and wait for them to find time and implement – something that in large companies may take weeks or months.
What if that ML / Deep Learning model – could not only help you optimize your current processes – but deliver a sustainable source of competitive advantage?
When a company has a Cement Production factory – It has an (very tangible) asset – that allow it compete in a specific field. The factory – both physically – and knowing how to operate it – delivers a “licence to compete/operate” – that a startup company does not have and would require significant investment to acquire, thus a source of competitive advantage.
What is the digital equivalent?
It is very common to quote Tesla (TSLA) nowadays – – as a part of their huge evaluation by the stock market – there is a fundamental belief that Tesla – with there now many cars on the street – all equipped with (at least) – radar, 8 cameras, and 12 ultrasonic sensors (Model 3). All of these sensors are streaming data back to Tesla – which they subsequently can use to improve the ML/AI to ensure that Tesla will be the company that reaches full autonomy as the first one.
The dataset – that enables Tesla to produce these ML / AI models – is the digital asset for Tesla.
Any incumbent in the market today – will be years behind Tesla on both the data collection and the understanding of how to apply it and use it.
Examples can be thought up in pretty much all industries:
Pharma (a dataset that delivers a model to predict how Cancer interacts with compounds) (or other diseases)
Fashion (a dataset that delivers a model to predict next years trends)
…
Digital for optimization.
There are plenty of examples where data is being collected and ML / AI models are trained and they deliver strong value back to the business:
Predictive maintenance (pro-actively maintain to prevent breakdown in production facilities)
Predict consumer behavior ( to keep stock accurate an be capable of delivering to demand)
.. continue the list.
If you’re not already looking into this – then I suggest to move in that direction and at lease scout the area.
These examples are for optimizations purposes – they accelerate already known processes and are good examples – but would most likely not be a source of strong, sustained competitive advantage.
How does it look in your industry?
Above examples delivers inspiration (and a way to divide things) – now is the time to figure out how it looks in the industry you’re competing.
What is the one (or more) digital assets – that would change the rules of the game in your industry – and are you currently building it ?
The Cement Factory up in example above – Thinking about building Digital Assets – being as important as a source of competition as the physical assets for a company and investing with equivalent management attentions to implementation and outcomes will deliver crucial first steps.
Assuming that the data that delivers the asset of tomorrow – will naturally spillover of todays processes seem to be a common line of thought – which is also what makes life hard for Data Scientists – because the data is simply not crafted for the purpose.
You probably wouldn’t establish your next cement factory in your office-building – just because those buildings were available?
Saw this one the other day – https://www.linuxin.dk/node/22861 – and was sent way down memory lane. 19 years back these days. A bit of history.
Linux and Open Source
Back in the late 1990s (yes, I was a bit late into the stuff with computers) – I learnt about SCO Unix – and subsequent Linux (as the free alternative) and go very amazed about:
What a community of people could do together
How big a set of LEGO bricks you could get for free just to play around with and improve
… and no this was “not toys” but real software with many years of legacy and hugely dedicated community behind it.
At university
Then I moved from the country side of Denmark (with 28.8 kbps dial-up modems at best) to Copenhagen – starting at DTU as a part of my Engineering education in Information Technology.
We clearly had the Linux fraction and the Windows fraction of people – but DTU was using Unix (Solaris) and Linux for quite a big set of courses – and SSLUG was a very active Linux User Group back then – over 5.000 members and 1-2 weekly meetup where likely minded people where meeting up.
Very soon – I found myself handing of Red Hat CD’s, Mandrake CD, etc, etc. Thus the idea was born.
Linuxpusher.dk
A webshop where people – for the mere cost of 20 DKK + shipping could get any Linux (and soon FreeBSD, etc, etc) CD using the national postal service (with day-to-day delivery).
And I even got an opportunity to strengthen my programming skills – thus the entire website was constructed in Perl/CGI – (Not that PHP thing that didnt really resemble a true programming language).
Linuxpusher.dk anno 2001 – Archive.org
Over the next years it grew – added merchandise, games, etc. – and the tower of CD-writers grew to 6 (concurrently) when highest. Then I needed to outsource that part of the shop and made a collaboration with a guy to hold inventory, pack and ship everything for me.
When at it highest (2003/2004’ish) – over 30 CD’s daily was leaving this shop – and it took a fair amount of time. In 2004 I needed to start my masters project at university – and having student job – on the side of this – ends didn’t really match up any more and I needed to sacrifice some of the activities. Thus the webshop transitioned to the next owner back then – and then to the next and yes – the post beginning this article – marks the latest transition.
Post 2004 the internet connectivity in Denmark grew and the actual need for a service like this declined – but Linux and Open Source continued to grow – thus the merchandise part still lives.
It is hard not to be a bit proud of having initiated something that is still alive (in a different shape and form) this many years later.
For the last weeks I’ve been catching up / deep diving on AWS Cloud platform – one of the more important components are EBS – which delivers foundation for a lot of other services including the things you build yourself within AWS – thus performance characteristics matters.
Normally organizations would be moving of Dell EMC , NetApp or similar enterprise grade storage – with a different set of performance characteristics – thus trying to create a comparison matters.
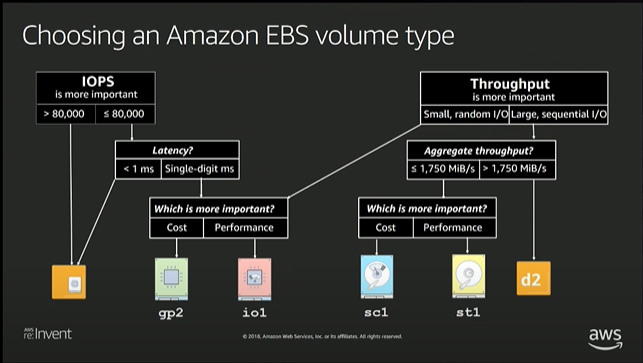
This video from re:invent describes a lot of good details about how to select an EBS volume type.
This looks a lot like the storage classes that can be build and setup using Ceph as a component in an internal setup – and has the same pro/con and limitations.
One of the limitations that are not that well highlighted is the impact on Single threaded IOPS – above 80.000 are really really nice – but it is aggregated performance – to compute the actual number of single threaded IOPS below fio benchmark can be used.
Long output – but I have highlighted the most important corners – avg latency (and also max).
So – the single threaded IOPS on EBS is approximately 1100 – which quite ok for a NAS/SAN or Software Defined Storage. But it actually means that if your application should use those 80.000 IOPS in the decision tree above it need to be capable of spreading IO over “at least” 80 parallel processes/threads or issue asynchronous IO to utillize those 80K IOPS.
Depending on what type of work your application does – then it may be excessively hard to do that.
This should be compared to a server with a local NVMe drive. This tweaktown image (article) depicts equivalent numbers from a Micron 9300 MAX NVMe drive and the comparable number is 40-45.000 IOPS or approximately 40x better.
Wonder if you current AWS instance suffers from lacking IO performance? – Processes stuck in state D in top, wait in dstat over 5 – would be clear indication.
Conclusion
There is a few key takeaways:
If you do migration – try to benchmark as above – where you’re coming from to where you’re heading – to avoid surprises.
You can get way better performance in AWS Instance stores – but there is no way to persist data over instance reboots (you need to do that at the application side)
If you can re-architect your application to be cloud-native / horizontally scalable then this fits excellent together. Cranking up concurrency is the way forward for performance here.
Do not – without careful consideration and benchmark move an application from direct attached NVMe/SSD to EBS – as they have performance characteristics that are much higher/better than EBS.
I have not practically managed go get the benchmark over 20K IOPS even with 64K provisioned IOPS and high queue-depth/concurrency – but I may be missing tweaks here.
Test – if you can just clone your system and do the move – that would be the best test.
One criticism could be: why do you benchmark random write performance?
There is a few good reasons. As much as random read performance is excessively important for application performance – memory is also very, very cheap and the OS (Linux / Windows) does a very good job at caching data locally and even getting high-memory instances and sequential performance is usually just dominated by the network bandwidth.
A bit of background – I have been working with a sizeable (Petabyte scale) on-premise setup for 10+ years. As a responsible manager – there was a struggle between external trends (e.g. Cloud will rule everything) and coming from the Open Source world where it is very transparent that most of what AWS provides is just an “apt or yum” away. In this post I’ll try to share a few perspectives.
Elasticity
Cloud is fantastic when it comes elasticity – If you have a need of 10.000 cpu-cores for just a few hours. Peak demands and bulk workloads where business processes are actually waiting for the results and it can speed up your R&D and eventually bring your product faster to market – then the case is pretty clear – you could even calculate it by figuring out what a week or two faster to market will do to your NPV estimation of your new product.
Agility
It is pretty awesome – with a credit-card in the one hand and a mouse in the other you can easily have infrastructure running close to your end users at all continents on the planet – probably before end of working day.
Security
Remember the CIA’s of security? The setups provided by cloud vendors deliver in terms of (A)vailability a setup that is very hard and costly to establish from ground up. I wont go into details with the (C)onfindentiality and (I)ntegrity in the cloud setups – as that would be a complete series of posts by themselves.
Cost
The first fix is free – AWS Free Tier is absolutely fantastic – you get the option of – at zero cost – to take most of the infrastructure for a run – If you havent done it allready – I really suggest you to do so – it is a very pleasant experience.
Second – when scaling up/out and getting sizeable data sizes in the 100TB+ or more – then AWS can actually become a significant cost-driver – depending on how the alternatives look – cost seem to be at least 3x higher – sometimes more than 10x – depending on where you are with your business – then that may actually make a difference.
Managed services
The managed services provided by AWS (and others) are really helpfull – example – a global relational database – scalable to 64TB with auto-scaling on the read-replica side. It do take at lease 1-2 very skilled internal people to maintain something similar.
Summary
The cloud is mature, scalable, robust and for some workloads/applications it delivers things that are very, very hard to achieve differently.
If you have:
Elastic need (Black friday peaks or other very dynamic workloads)
Need for agility/speed – or lack of outlook for future needs.
Can overview the costs.
Then I strongly suggest you go have a look. If you care about the C and I above – Cloud may be at your benefit – or the other way around – there is a need to evaluate.
On the other hand – if you’re sitting at scale and already concerned with your internal costs – then moving to the cloud may very well be a move in the wrong direction for you.
As an example: queue-it.net (Web based queuing system for busy websites) – is a very strong fit to AWS – as it truly benefits from the elasticity.

{kind=link}